情報発信
今回は、SAPユニコードシステムのデータ入出力で使われるエンコード方式UTF-8についてお話しします。
UTF-8
第2回のコラムで、ユニコードには、128の群、256の面、256の区、256の点の組み合わせから成る20億個の文字集合であるUCS-4とその部分集合であるUCS-2の2 通りの文字集合があると説明しました。UTF-8は、UCS-4の文字集合を完全に対応できるエンコード方式です。UTF-8は、UCS-4に定義された文字を1バイトから6バイトまでのバイト列に符号化します。また、UTF-8の特長として、ASCIIコードとの互換性が挙げられます。 ASCIIコードに収録されている文字は、UTF-8で符号化してもASCIIコードとバイト列が同じになります。つまり、アルファベットや数字をユニコードで処理しても、UTF-8で符号化すれば、ASCIIコードで処理した場合と同じバイト列になるのです。
一方、ASCIIコードで定義されていない文字は、2から6バイトのバイト列に符号化されます。例えば、日本語文字であれば、半角カナ、全角かな、JIS第一、第二水準漢字、JIS第三、第四水準漢字の一部、<や>などの記号が3バイト、JIS第三、第四水準漢字の残りが4バイトでエンコードされます。そして、これらの文字は、シフトJISで符号化したバイト列とは同じになりません。
UTF-8の種類
第3回のコラムで、エンディアンによるUTF-16の違いについて説明しましたが、UTF-8には、エンディアンによる違いはありません。エンディアンの判別が不要なので、本来ならばBOMは必要ないのですが、UTF-8を扱うソフトウエアによっては、バイト列の先頭にUTF-8を表す BOMを付加することがあります。そこで、BOMが付いたものをUTF-8、BOMが付いていないものをUTF-8Nと区別して呼ぶことがあります。メモ帳を例にして説明します。メモ帳で文字コードUTF-8を指定して、「あ」という文字をファイルに保存すると、ファイル全体のバイト列は、0xEFBBBFE38182になります。この場合、バイト列の先頭の3バイトEFBBBFがUTF-8を表すBOMで、E38182が「あ」を符号化したバイト列になります。
一方、フリーのエディターソフトTeraPadで文字コードUTF-8Nを指定して「あ」をファイルに保存すると、BOMが先頭に付加されないので、ファイル全体のバイト列は、0xE38182になります。
日本語と英語の違い
SAPユニコードシステムでは、GUIを含む外部システムとのデータ入出力のエンコード方式にUTF-8を採用しています。では、なぜSAPユニコードシステムは、内部処理とデータ入出力でエンコード方式を使い分けるのでしょうか。SAP社の公開文書Supported Languages in Unicode SAP Systemsには、データ入出力にUTF-8を採用した理由として、ASCII文字との互換性やエンディアンの判別が不要である点、XMLがエンコード方式にUTF-8を採用している点などが挙げられています。アメリカを含む英語圏の多くのSAPユーザへの配慮、エンディアンの違うベンダーのハードウエアへの対応、SOAなどのシステム連携などを考慮すると、データ入出力にUTF-8を使用するのは妥当なことなのかもしれません。
例えば、英語しか使わないSAPユーザがMDMPシステムからユニコードシステムにアップグレードした場合、システム内部のデータは大幅に変わりますが、システムインタフェース部分は、UTF-8とASCIIコードで符号化の結果が同じなので、受渡されるデータに違いがありません。従って、ユニコードシステムに切り替えても、インタフェースの部分は、システムを修正する必要がありません。
しかし、SAPシステムで日本語を使用しているユーザの場合は、事情が異なります。MDMPシステムでは、内部処理と入出力のエンコード方式にシフトJISが使われていたので、インタフェース部分は、バイト固定長でデータを取り扱うことができました。しかし、ユニコードシステムは、内部ではUTF-16で文字を2バイトで処理し、インタフェース部分では、UTF-8で文字を1バイトから4バイトの可変長データに変換して処理します。従って、UTF-8から シフトJISに再変換しても、データをバイト固定長で処理することはできません。
日本語のダウンロード
では、実際にSAPシステムからデータをダウンロードして、MDMPシステムとユニコードシステムの違いを確認してみます。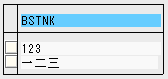
この画面は、データブラウザー機能を使って、受注伝票の得意先発注番号 (VBAK-BSTNK) という文字型長さ20の項目を表示したものです。上段に数字3字、下段に漢字3字の値があります。GUIのメニューから、システム>一覧>保存>ローカルファイルを選択して、パソコンに得意先発注番号をダウンロードしてみます。
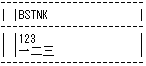
MDMPシステムからシフトJISで得意先発注番号をダウンロードして、メモ帳を使って等幅フォントで照会してみると、次のように上段、下段で得意先発注番号が揃って表示されます。
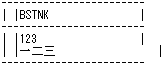
一方、ユニコードシステムからUTF-8でダウンロードしてシフトJISに変換した場合は、次のように最後の縦罫線がずれて表示されます。
なぜ、ユニコードシステムでは、表示がずれたのでしょうか。ダウンロードしたデータのバイト列を比較してみます。
下の表は、MDMPシステムからシフトJISでダウンロードした得意先発注番号を16進数で表記したバイト列です。上段の先頭0×31、0×32、0×33は、数字の1,2,3で、下段の先頭0x88EA、0x93F1、0x8E4Fは、シフトJISで符号化された漢字の一、二、三です。上段、下段とも、値の後ろに空文字0×20が追加されていますが、全体の長さは、いずれも20バイトであることが分かります。
|
バイト |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
上 |
31 |
32 |
33 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
||||||
|
下 |
88 |
EA |
93 |
F1 |
8E |
4F |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
下の表は、ユニコードシステムでダウンロードしたUTF-8のバイト列です。上段の先頭3バイトは、数字の“123″で、シフトJISと同様にASCIIコードと同じバイト列になっています。一方、下段の先頭0xE4B880、0xE4BA8C、0xE4B889は、UTF-8で符号化された漢字の一、二、三のバイト列です。内部処理では、UTF-16で同じ2バイト、文字型長さ1で処理された数字と漢字が、ダウンロード時にUTF-8で符号化され、1文字のバイト長に差が発生して、得意先発注番号全体のバイト長が変わったことが分かります。
|
バイト |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
上 |
31 |
32 |
33 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
||||||
|
下 |
E4 |
B8 |
80 |
E4 |
BA |
8C |
E4 |
B8 |
89 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
下の表は、上の UTF-8 のデータをシフト JIS に変換したバイト列です。合計 9 バイトで符号化されていた下段の漢字が 6 バイトになっていることが分かります。しかし、シフト JIS に変換しても、上段と下段の得意先発注番号には 3 バイトの差があります。
|
バイト |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
上 |
31 |
32 |
33 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
||||||
|
下 |
88 |
EA |
93 |
F1 |
8E |
4F |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
20 |
MDMPシステムは、文字型1個分の長さが1バイトで、シフトJISで文字を符号化します。従って、数字の “123″ は、文字列の長さが3になり、得意先発注番号項目の残りの長さ17には空文字0×20が更新されます。漢字の「一二三」の場合は、1文字当たり2バイトで符号化されるので、文字列の長さが6になり、残りの長さ14に空文字が更新されます。そして、シフトJISのままでシステム外部に出力されるので、ダウンロードされるデータは、20バイトになります。
ユニコードシステムは、文字型1個分の長さが2バイトで、内部処理ではUTF-16で文字を符号化します。従って、数字の“123″も漢字の「一二三」も6バイト、文字型長さ3で処理され、残りの長さ17に空文字が更新されます。そして、UTF-8で符号化してシステム外部に出力すると、数字と空文字が1バイト、漢字が3バイトのバイト列に変換されるので、数字3つの文字列の3バイトと漢字3つの文字列の9バイトの間に6バイトの差が発生します。そして、UTF-8のデータをシフトJISに変換すると、数字と空文字が1バイト、漢字が2バイトで符号化されるので、上段の得意先発注番号は、数字の3バイト、と空文字の17バイトで合計20バイトのデータになり、下段は、漢字6バイトと空文字17バイトで合計 23バイトのデータになります。シフトJISに変換しても、結果的に3バイトの差異が発生してしまうのです。
つまり、ユニコードシステムの内部では、UTF-16で同じバイト長で処理されたデータでも、システム外部に出力すると、UTF-8のままでも、シフトJISに再変換しても、バイト長が可変することになります。この現象は、パソコンへのデータダウンロードに限ったものではありません。IDocやファイルポートを使ったデータ出力の場合でも同じことが発生します。